Tracking
2D/3D Tracking Benchmark:
The primary metric we use to evaluate tracking is MOTA, which combines false positives, false
negatives, and id switches. We also report MOTP, which is a measure of the localisation
accuracy of the tracking algorithm. Rank is determined by MOTA. We require
intersection-over-union to be greater than 50% for 2D tracking and 30% for 3D tracking.
MOTA is given by:
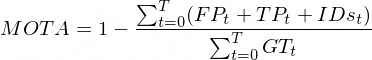
where t indicates the frame number, T is the total number of frames, FP is the number of
false positives in frame t , FN the number of false negatives in frame t, IDs the number of id
switches in frame t, and GT is the
number of ground truth objects of frame t.
MOTP is given by:
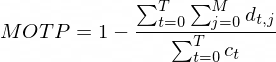
where i indicates frame number, t is the total number of frames, M is the total number of
objects in frame i , ci
is the number of matches between predictions and ground truth in frame i
, and d is the intersection over union distance (1-IOU) of a particular match.
i,j
To evaluate 2D tracking, we run Clear-MOT metrics using an IoU threshold of 0.5. To evaluate
3D tracking, the 3D IoU is calculated using a combination of the Sutherland-Hodgman algorithm
and the shoelace formula (surveyor's formula) to determine the area of intersection. The
Sutherland Hodgman algorithm is an algorithm used to clip polygons. A 3D-IoU threshold of 0.5
is used to determine matches.
Our benchmark contains OSPA and HOTA too.
Preparing Tracking Submissions:
Your submission will consist of a single zip file. Please ensure that the sequence folders are
directly
zipped and that you do not zip their parent folder. The folder structure and content of this
file (e.g.
result files) have to comply with the KITTI tracking format
described here.
Expected
Directory Structure of 2D/3D Tracking Submissions:
CIWT/data/0000.txt
/0001.txt
/0002.txt
...
/0026.txt
Each of the txt file corresponding to a test sequence, ordering alphabetically. eg. 0000.txt corresponds to sequence cubberly-auditorium-2019-04-22_1 and 0026.txt corresponds to sequence tressider-2019-04-26_3.
2D/3D tracking File and Label Format:
All values (numerical or strings) are separated via
spaces, each row
corresponds to one object. The 18 columns (17 values + 1 score value) represent:
frame, track id, type, truncated,occluded, alpha, bb_left, bb_top, bb_width, bb_height, x, y, z,
height, width, length, rotation_y, score
The details are given below:
#Values
Name
Description
1
frame
Frame within the sequence where the object appearers
1
track id
Unique tracking id of this object within this sequence
1
type
Describes the type of object: 'Pedestrian' only
1
truncated
Integer (0,1,2) indicating the level of truncation.
Note that this is in contrast to the object detection
benchmark where truncation is a float in [0,1].
1
occluded
Integer (0,1,2,3) indicating occlusion state:
0 = fully visible, 1 = partly occluded
2 = largely occluded, 3 = unknown
1
alpha
Observation angle of object, ranging [-pi..pi]
4
bbox
2D bounding box of object in the image (0-based index):
contains left, top, right, bottom pixel coordinates
3
location
3D object location x,y,z in camera coordinates (in meters)
3
dimensions
3D object dimensions: height, width, length (in camera coordinate - y_size, x_size, z_size; in meters).
1
rotation_y
Rotation ry around Y-axis in camera coordinates [-pi..pi]
1
score
Only for results: Float, indicating confidence in
detection, needed for p/r curves, higher is better.
The conf value contains the detection confidence in the det.txt files. For a submission, it acts as
a flag whether the entry is to be considered. A value of 0 means that this particular instance is
ignored in the evaluation, while any other value can be used to mark it as active. For submitted
results, all lines in the .txt file with a confidence of 1 are considered. Fields which are not
used,
such as 2D bounding box for 3D tracking or location, dimension, and rotation_y for 2D tracking,
must be set to -1.
Note incorrect submission format may result error in evaluation or abnormal
results.


